I just completed Microsoft's Reinforcement Learning Explained course
by Patrick Lee on 01 Jul 2019 in categories BigData tech with tags AI CNTK Jupyter notebooks lifelong learning PythonYesterday I completed what I have found to be the most demanding course so far on the Microsoft Professional Program for Artificial Intelligence, Reinforcement Learning Explained. It took me 66.5 hours (more than twice as long as previous edX courses have taken me) and my final mark was 94%.
This was my 9th course on the professional program, and this month (July 2019) I am taking the final course, a capstone project designed to test a lot of the material learned during the previous courses. I have had a quick look at this (I couldn't until now because the capstone courses can only be taken in the first month of every calendar quarter), and it is an interesting project: developing an algorithm to successfully classify sound files as to whether the accent used is Canadian, English or Indian! So I am looking forward to doing that.
Once I have finished the AI professional program, I will write up an overview of it (as I did here with the Data Science and here with the Big Data professional programs), but here are some brief comments about the Reinforcement Learning Explained course.
Arguably this is the most actuarial/mathematical of all the courses I have done so far, whether on data science, big data or AI. It involves optimisation in a stochastic process, and includes dynamic programming and the Bellman equations, which I remember doing at university a few decades ago. Quite a lot of python programming too.
Reinforcement Learning includes algorithms similar to the ones used by Alpha Go Zero (the program that managed to beat Alpha Go, the program that had beaten the human world champion at Go). Alpha Go taught itself initially by studying many previous games played by humans. Alpha Go Zero was entirely self taught: i.e. all it started off with was the rules of Go, and it learned by playing itself and gradually improving!
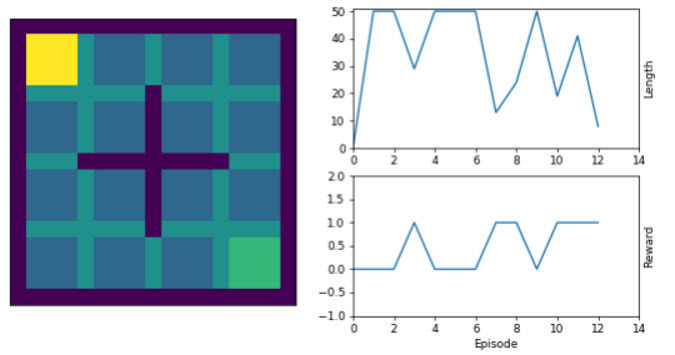
The image at the top of this article is of a much simpler problem than Go, a Simple Room Environment in which the objective is for an agent (think of this as a player in a game) to learn how to reach the bottom right square as quickly as possible starting from the top left square. There are walls in place which block certain routes. The agent is represented by the yellow square.
The image shows the progress of an agent using a SARSA (State Action Reward State Action) algorithm as it learns during 12 stochastic episodes (plays of the game). The game stops after 50 moves or if the goal (the bottom right cell) is reached before then. The Length in the charts is the number of moves (with 50 normally denoting failure to reach the goal), and the Reward is the total reward received during the episode (a score of 1 means that the goal was reached).
You can see from the charts that towards the end of the 12 episodes, the agent seems to have learnt to reach the goal consistently (i.e. it will no longer fail). This is not necessarily going to be the case however, nor would this necessarily be optimal: the agent may have found a lengthy route to reach the goal, so often in Reinforcement Learning problems, it is necessary to continue exploring from time to time (e.g. under an epsilon greedy process, see https://en.wikipedia.org/wiki/Multi-armed_bandit) in the hope of finding an even better route.
PS I have complained to edX about the course having been advertised as only taking 24 to 36 weeks yet containing a lot more material and lab work than previous courses. And about other problems too: very poor English in the material and questions, very poor pronunciation in some of the course videos (and hence the video transcripts, which clearly were never checked by edX), no responses from edX to discussion forum posts after 2 months! I hope edX will sort some or all of these problems out in future versions of the course, but be forewarned that it may take considerably longer than other courses in case they have not.